Catalyst, Fastai, Ignite and Pytorch-Lightning are all amazing frameworks but which one should I use for project x? I have been asking myself the same question and it is not an easy answer.
There are several factors at play and framework selection also depends on your background. I will outline some basic statistics and library codestyle examples. I believe it is important to be able to delve into the source code of these libraries when you inevitably get stuck on problem/can’t work out how to implement something or want to debug your code.
Catalyst
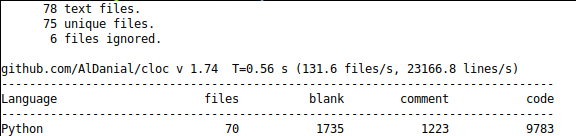
I started to use Catalyst last year and really liked the pre-built notebooks showing examples for image classification and segmentation. I have placed in top 1% in a couple of image segmentation and an image classification competition using it. The catalyst github repo documents code from mutiple high competition placings.

class SupervisedRunner(Runner):
"""Runner for experiments with supervised model."""_experiment_fn: Callable = SupervisedExperimentdef __init__(
self,
model: RunnerModel = None,
device: Device = None,
input_key: Any = "features",
output_key: Any = "logits",
input_target_key: str = "targets",
):
"""
Args:
model (RunnerModel): Torch model object
device (Device): Torch device
input_key (Any): Key in batch dict mapping for model input
output_key (Any): Key in output dict model output
will be stored under
input_target_key (str): Key in batch dict mapping for target
"""
super().__init__(
model=model,
device=device,
input_key=input_key,
output_key=output_key,
input_target_key=input_target_key,
)def _init(
self,
input_key: Any = "features",
output_key: Any = "logits",
input_target_key: str = "targets",
):
"""
Args:
input_key (Any): Key in batch dict mapping for model input
output_key (Any): Key in output dict model output
will be stored under
input_target_key (str): Key in batch dict mapping for target
"""
self.experiment: SupervisedExperiment = Noneself.input_key = input_key
self.output_key = output_key
self.target_key = input_target_keyif isinstance(self.input_key, str):
# when model expects value
self._process_input = self._process_input_str
elif isinstance(self.input_key, (list, tuple)):
# when model expects tuple
self._process_input = self._process_input_list
elif self.input_key is None:
# when model expects dict
self._process_input = self._process_input_none
else:
raise NotImplementedError()if isinstance(output_key, str):
# when model returns value
self._process_output = self._process_output_str
elif isinstance(output_key, (list, tuple)):
# when model returns tuple
self._process_output = self._process_output_list
elif self.output_key is None:
# when model returns dict
self._process_output = self._process_output_none
else:
raise NotImplementedError()
An example of the starting code for the SupervisedRunner in catalyst is shown above.
What I like: The dataloading, transforms, model are all pure pytorch, only the training loop is different, with lots of boilerplate pytorch code simplified. The team implements latest best training practices.
What is hard: Catalyst relies heavily on callbacks and it requires a bit of work to understand how to use and modify these. Also some of the built-in features may not have clear examples on how to use them.
When to use: If you are at an intermediate level+ researcher or kaggle (or other platform) competitor.
Fastai
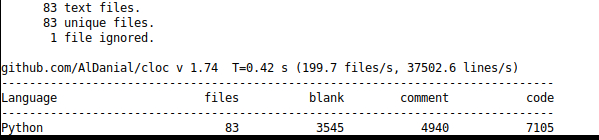
I have been using Fastai since 2017 which then was using Tensorflow, and first started using Pytorch though the training corses (parts 1&2 in 2017,2018,2019 and 2020). Out of the libraries here, Fastai to me feels the higest level. Not only this but Fastai manages to do this with a fairly small codebase which is impressive. Note however the code-style is more densely packed than the other libraries, and if formatted in a black the lines of code would exand out significantly.
@log_args(but='dls,model,opt_func,cbs')
class Learner():
def __init__(self, dls, model, loss_func=None, opt_func=Adam, lr=defaults.lr, splitter=trainable_params, cbs=None,
metrics=None, path=None, model_dir='models', wd=None, wd_bn_bias=False, train_bn=True,
moms=(0.95,0.85,0.95)):
path = Path(path) if path is not None else getattr(dls, 'path', Path('.'))
if loss_func is None:
loss_func = getattr(dls.train_ds, 'loss_func', None)
assert loss_func is not None, "Could not infer loss function from the data, please pass a loss function."
self.dls,self.model = dls,model
store_attr(but='dls,model,cbs')
self.training,self.create_mbar,self.logger,self.opt,self.cbs = False,True,print,None,L()
self.add_cbs([(cb() if isinstance(cb, type) else cb) for cb in L(defaults.callbacks)+L(cbs)])
self("after_create")@property
def metrics(self): return self._metrics
@metrics.setter
def metrics(self,v): self._metrics = L(v).map(mk_metric)def _grab_cbs(self, cb_cls): return L(cb for cb in self.cbs if isinstance(cb, cb_cls))
def add_cbs(self, cbs): L(cbs).map(self.add_cb)
def remove_cbs(self, cbs): L(cbs).map(self.remove_cb)
def add_cb(self, cb):
old = getattr(self, cb.name, None)
assert not old or isinstance(old, type(cb)), f"self.{cb.name} already registered"
cb.learn = self
setattr(self, cb.name, cb)
self.cbs.append(cb)
return selfdef remove_cb(self, cb):
if isinstance(cb, type): self.remove_cbs(self._grab_cbs(cb))
else:
cb.learn = None
if hasattr(self, cb.name): delattr(self, cb.name)
if cb in self.cbs: self.cbs.remove(cb)@contextmanager
def added_cbs(self, cbs):
self.add_cbs(cbs)
try: yield
finally: self.remove_cbs(cbs)@contextmanager
def removed_cbs(self, cbs):
self.remove_cbs(cbs)
try: yield self
finally: self.add_cbs(cbs)def ordered_cbs(self, event): return [cb for cb in sort_by_run(self.cbs) if hasattr(cb, event)]def __call__(self, event_name): L(event_name).map(self._call_one)
Example code from the Learner class in fastai is shown above.
What I like: The community is amazing. You can find a solution to pretty much any problem there. The courses are really good too, and at the moment I am working through the Fastai book. I am really grateful to Jeremy and the Fastai team for introducing me to a lot of new concepts. The team keeps up-to date with research and implements latest best training practices.
What is hard: The Fastai dataloder is different to the other 3 frameworks where (which all use the pytorch dataloader), and is a core piece of Fastai. Maybe not so much hard as different, it takes time to get your head around the datablocks API.
When to use: If you are a beginner through expert and like the way you can very quickly implement working code.
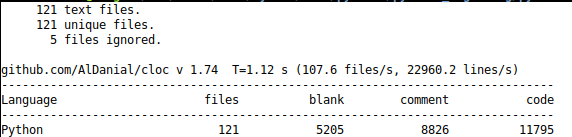
Ignite
I have only breifly used Ignite, the library does have some interesting features. Out of the 4 lbraries reviewed, Ingite seems to allow you the closest coupling to pure pytorch, and I am looking forward to experimenting more with it.
The Ignite codebase is the smallest of the 4 frameworks.
def run(self, data: Iterable, max_epochs: Optional[int] = None, epoch_length: Optional[int] = None,) -> State:
"""Runs the `process_function` over the passed data.Engine has a state and the following logic is applied in this function:- At the first call, new state is defined by `max_epochs`, `epoch_length` if provided. A timer for
total and per-epoch time is initialized when Events.STARTED is handled.
- If state is already defined such that there are iterations to run until `max_epochs` and no input arguments
provided, state is kept and used in the function.
- If state is defined and engine is "done" (no iterations to run until `max_epochs`), a new state is defined.
- If state is defined, engine is NOT "done", then input arguments if provided override defined state.Args:
data (Iterable): Collection of batches allowing repeated iteration (e.g., list or `DataLoader`).
max_epochs (int, optional): Max epochs to run for (default: None).
If a new state should be created (first run or run again from ended engine), it's default value is 1.
If run is resuming from a state, provided `max_epochs` will be taken into account and should be larger
than `engine.state.max_epochs`.
epoch_length (int, optional): Number of iterations to count as one epoch. By default, it can be set as
`len(data)`. If `data` is an iterator and `epoch_length` is not set, then it will be automatically
determined as the iteration on which data iterator raises `StopIteration`.
This argument should not change if run is resuming from a state.Returns:
State: output state.Note:
User can dynamically preprocess input batch at :attr:`~ignite.engine.events.Events.ITERATION_STARTED` and
store output batch in `engine.state.batch`. Latter is passed as usually to `process_function` as argument:.. code-block:: pythontrainer = ...@trainer.on(Events.ITERATION_STARTED)
def switch_batch(engine):
engine.state.batch = preprocess_batch(engine.state.batch)Restart the training from the beginning. User can reset `max_epochs = None`:.. code-block:: python# ...
trainer.run(train_loader, max_epochs=5)# Reset model weights etc. and restart the training
trainer.state.max_epochs = None
trainer.run(train_loader, max_epochs=2)"""
if not isinstance(data, Iterable):
raise TypeError("Argument data should be iterable")if self.state.max_epochs is not None:
# Check and apply overridden parameters
if max_epochs is not None:
if max_epochs < self.state.epoch:
raise ValueError(
"Argument max_epochs should be larger than the start epoch "
"defined in the state: {} vs {}. Please, set engine.state.max_epochs = None "
"before calling engine.run() in order to restart the training from the beginning.".format(
max_epochs, self.state.epoch
)
)
self.state.max_epochs = max_epochs
if epoch_length is not None:
if epoch_length != self.state.epoch_length:
raise ValueError(
"Argument epoch_length should be same as in the state, given {} vs {}".format(
epoch_length, self.state.epoch_length
)
)if self.state.max_epochs is None or self._is_done(self.state):
# Create new state
if max_epochs is None:
max_epochs = 1
if epoch_length is None:
epoch_length = self._get_data_length(data)
if epoch_length is not None and epoch_length < 1:
raise ValueError("Input data has zero size. Please provide non-empty data")self.state.iteration = 0
self.state.epoch = 0
self.state.max_epochs = max_epochs
self.state.epoch_length = epoch_length
self.logger.info("Engine run starting with max_epochs={}.".format(max_epochs))
else:
self.logger.info(
"Engine run resuming from iteration {}, epoch {} until {} epochs".format(
self.state.iteration, self.state.epoch, self.state.max_epochs
)
)self.state.dataloader = data
return self._internal_run()
Code from the run method of the Engine class is shown above.
Pytorch-Lightning
I have been using Pytorch-Lightning on and off for a few months. I have been doing some experimenting with pre-trained transformers from the huggingface library with it.
def fit(
self,
model: LightningModule,
train_dataloader: Optional[DataLoader] = None,
val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,
datamodule: Optional[LightningDataModule] = None,
):
r"""
Runs the full optimization routine.Args:
datamodule: A instance of :class:`LightningDataModule`.model: Model to fit.train_dataloader: A Pytorch DataLoader with training samples. If the model has
a predefined train_dataloader method this will be skipped.val_dataloaders: Either a single Pytorch Dataloader or a list of them, specifying validation samples.
If the model has a predefined val_dataloaders method this will be skipped"""
# bookkeeping
self._state = TrainerState.RUNNING# ----------------------------
# LINK DATA
# ----------------------------
# setup data, etc...
self.train_loop.setup_fit(model, train_dataloader, val_dataloaders, datamodule)# hook
self.data_connector.prepare_data(model)# bookkeeping
# we reuse fit in .test() but change its behavior using this flag
self.testing = os.environ.get('PL_TESTING_MODE', self.testing)# ----------------------------
# SET UP TRAINING
# ----------------------------
self.accelerator_backend = self.accelerator_connector.select_accelerator()
self.accelerator_backend.setup(model)# ----------------------------
# INSPECT THESE FOR MAIN LOOPS
# ----------------------------
# assign training and eval functions... inspect these to see the train and eval loops :)
self.accelerator_backend.train_loop = self.train
self.accelerator_backend.validation_loop = self.run_evaluation
self.accelerator_backend.test_loop = self.run_evaluation# ----------------------------
# TRAIN
# ----------------------------
# hook
self.call_hook('on_fit_start')results = self.accelerator_backend.train()
self.accelerator_backend.teardown()# ----------------------------
# POST-Training CLEAN UP
# ----------------------------
# hook
self.call_hook('on_fit_end')# hook
self.teardown('fit')
if self.is_function_implemented('teardown'):
model.teardown('fit')# return 1 when finished
# used for testing or when we need to know that training succeededif self._state != TrainerState.INTERRUPTED:
self._state = TrainerState.FINISHED
return results or 1
An example of code from the fit method in pytorch Trainer is shown above
What I like: The examples for porting pytorch code to pl. For small codebases it is fairly easily to port over pytorch code.
What is hard: I have found it tricky to debug for example my implementation of loading a pre-trained checkpoint into a new model for inference. Also there are only a few example implementations in the codebase.
When to use: Intermediate+ when you have mastered the basics of training models in pytorch.
The winner
I don’t think there is a clear winner, each of the libraries has it’s strengths and weaknesses (to me). I’d encourage you to explore each and see which library gels with you.