Adrian GAtrificial Neural Network Basics: Part 1 — NeuronsArtificial Neural Networks are computational models inspired by human and animal brains. A fundamental collection and processing unit of…Oct 20, 2023Oct 20, 2023
Adrian GBudget Linux utility serverI often run out of hard drive space and was looking for a storage server that could also function as a spare CPU compute machine and…Dec 23, 2022Dec 23, 2022
Adrian GPytorch frameworks, a few comparissonsCatalyst, Fastai, Ignite and Pytorch-Lightning are all amazing frameworks but which one should I use? I have been asking myself the same…Oct 25, 2020Oct 25, 2020
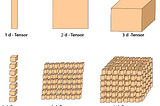
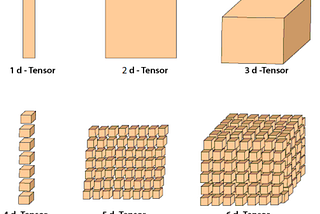
Adrian GPytorch tensor operationsThis post covers some of the key operations used in pytorchAug 29, 2020Aug 29, 2020
Adrian GNumpy AxesThis post covers a quick overview of axes in numpy (NB both numpy and pytorch use same representation)Aug 29, 2020Aug 29, 2020
Adrian GSumperMicro IPMI when a board wont postI bought a used Supermicro X9DRi-LN4F+ from ebay to use for datascience projects involving large datasets where having >128MB RAM and 20+…May 31, 20201May 31, 20201
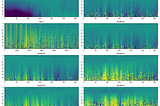
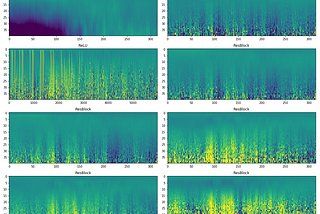
Adrian GBatch Norm and Transfer Learning — whats going on?A commonly used technique in deep-learning is transfer-learning, whereby the learned weights of a model that was pre-trained on one…Jun 24, 20191Jun 24, 20191
Adrian GGumtree sale scammerGumtree is a UK and Australia website for used item sales, a bit like ebay but more personable. Recently I put an item up for sale, an RTX…May 31, 2019May 31, 2019
Adrian GHitting a brick wall in a Kaggle CompetitionHere I am reviewing my experience in the VSB Power Line Fault Detection Kaggle Competition.Apr 25, 2019Apr 25, 2019
Adrian GBuilding a Multi-GPU Deep Learning Machine on a budgetHere’s another story on building your own deep learning rig, containing the information I wish I had known a couple of years ago.Mar 11, 20196Mar 11, 20196